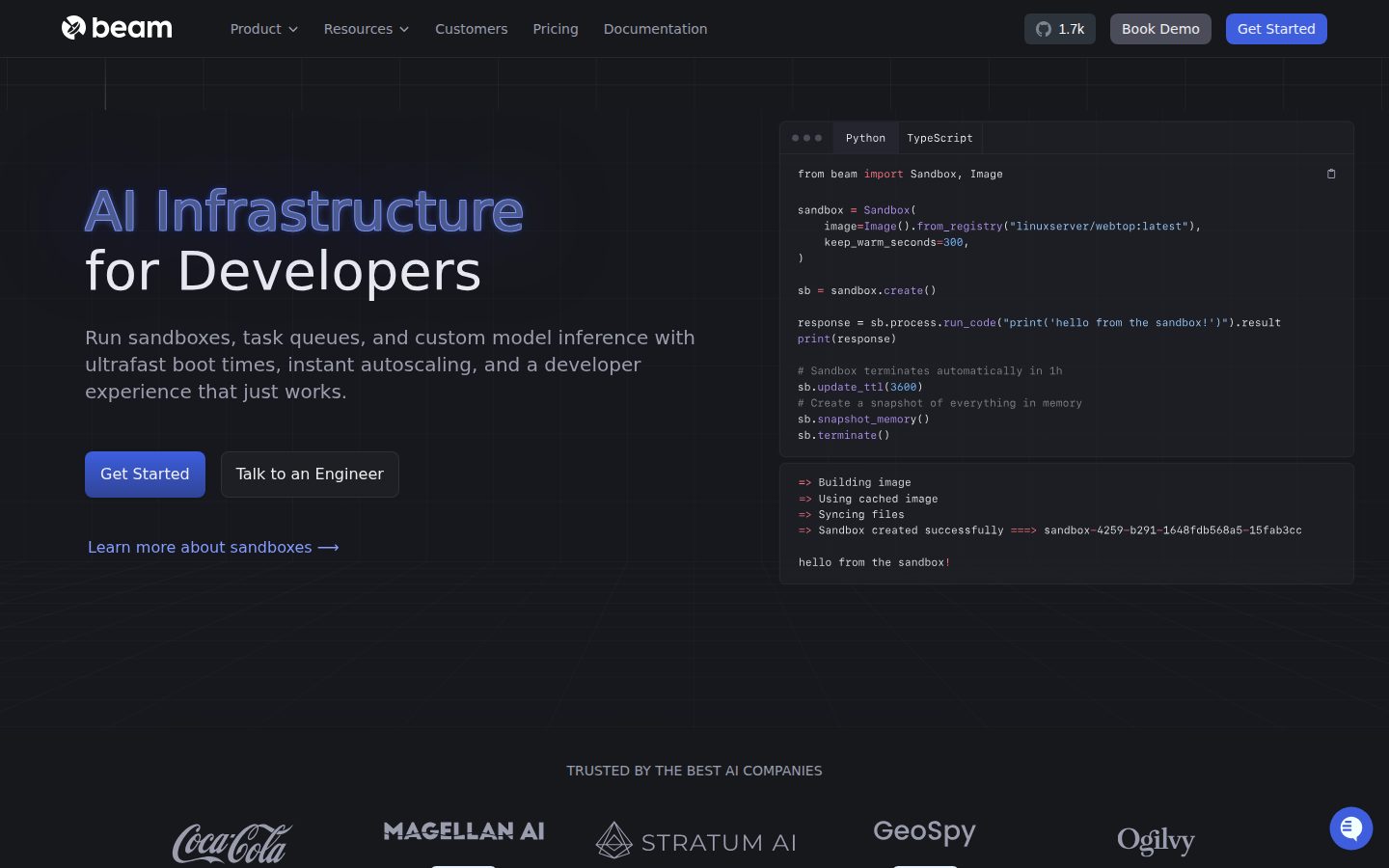
Developers interact with Beam primarily through a Python SDK, where switching hardware types requires changing a single line of code. Workloads are deployed from the CLI or via GitHub Actions CI/CD integration. Local debugging uses the same configuration as production, reducing environment mismatch. Containers support Docker-in-Docker and multiple workers per container for vertical scaling.
Beam distinguishes itself with a set of composable primitives: durable task queues for async workloads, secure sandboxed execution environments for running LLM-generated code, custom model inference endpoints that accept user-supplied Docker images, and support for training and fine-tuning models ranging from SLMs to diffusion models. It also supports deploying Streamlit and Gradio frontends, Jupyter notebooks, and headless or headed Chromium instances for web scraping at scale.
Beam targets machine learning engineers and AI developers who need on-demand GPU access without managing virtual machines or cloud provider tooling. Pricing is usage-based, and new users receive $30 in free credits refreshed monthly. Beam competes in a category alongside AWS SageMaker, Google Vertex AI, Modal, and RunPod, with user testimonials specifically citing it as easier and more cost-efficient than SageMaker and Vertex AI.
The platform is open source and supports bring-your-own-cloud deployment, allowing teams to run workloads on their own infrastructure rather than Beam's managed cloud. Integration with GitHub Actions enables automated deployments within existing CI/CD pipelines.