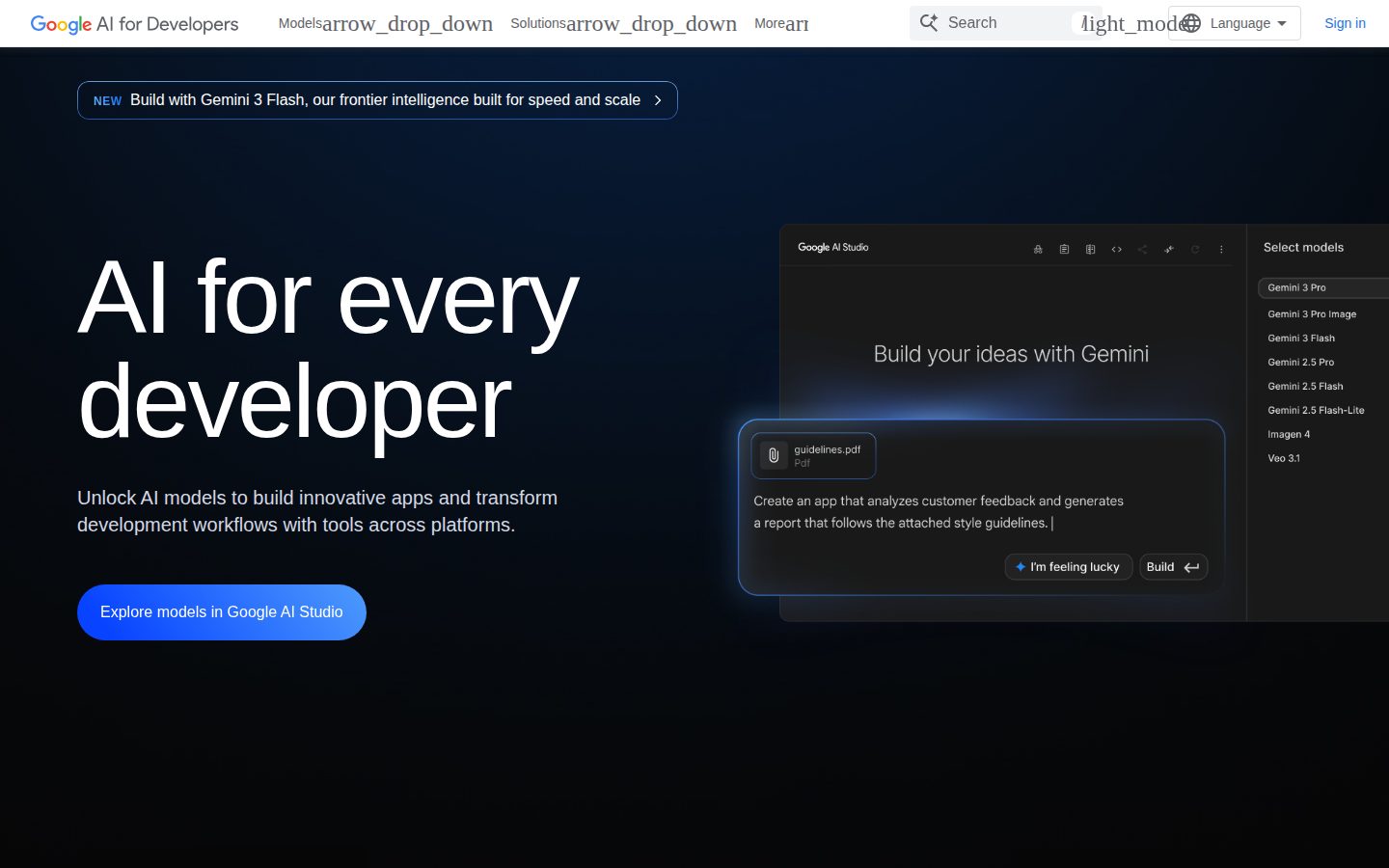
Google Gemini API is a developer platform that provides programmatic access to Google's family of Gemini large language models. The API enables developers to integrate advanced AI capabilities into their applications, websites, and services through standard REST API calls.
The platform supports various Gemini model variants, including text-only and multimodal models that can process text, images, and other input types. Developers can use the API for tasks such as text generation, content creation, question answering, code generation, and analysis of multimodal content. The API includes features like safety filters, adjustable model parameters, and structured output formatting.
The service is designed for developers, software companies, and organizations looking to incorporate AI functionality into their products. It competes with other AI API providers like OpenAI, Anthropic, and Microsoft Azure AI services in the growing market for AI-as-a-service platforms.
Google provides the API through its AI development platform with comprehensive documentation, code examples, and integration guides. The service follows a usage-based pricing model where developers pay based on the number of API calls and tokens processed.