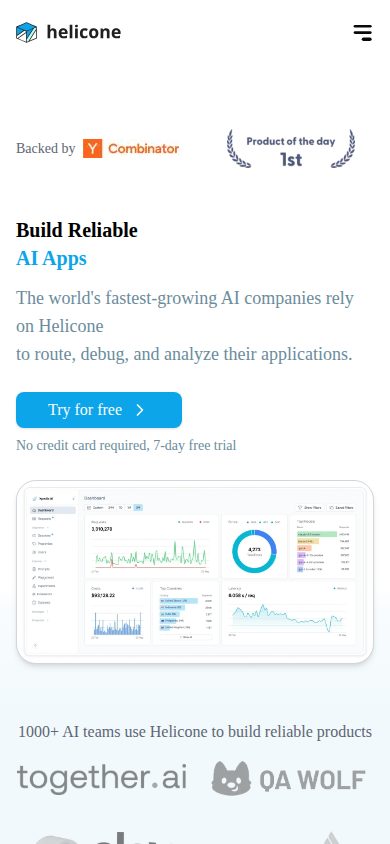
Developers integrate Helicone by routing their LLM API calls through Helicone's gateway, typically requiring only a one-line change to the base URL in existing code. From there, every request is logged and surfaced in a dashboard where users can view spend breakdowns by model, track latency over time, and inspect individual requests for debugging. Custom properties can be attached to requests to segment analytics by user, session, feature, or any other dimension meaningful to the team.
Beyond passive monitoring, Helicone includes features designed to reduce costs and improve performance. Request caching stores responses to repeated prompts to avoid redundant API calls. Model-swapping allows teams to redirect traffic between providers or model versions without redeploying. The platform integrates with popular AI frameworks and supports authentication via header-based tokens, making it compatible with most existing LLM workflows.
Helicone targets software developers and AI engineering teams who use models like GPT-4, Claude, or other hosted LLMs at scale and need visibility into operational costs and reliability. The product is open-source and can be self-hosted on your own infrastructure, or used as a managed cloud service. Competitors in the LLM observability category include Portkey, LangSmith, and Weights & Biases.
The open-source codebase is available on GitHub, enabling self-hosted deployments for teams with data residency or compliance requirements. Cloud and self-hosted configurations both support the same core feature set, with documentation covering quick-start setup, gateway integration, and advanced custom property tracking.