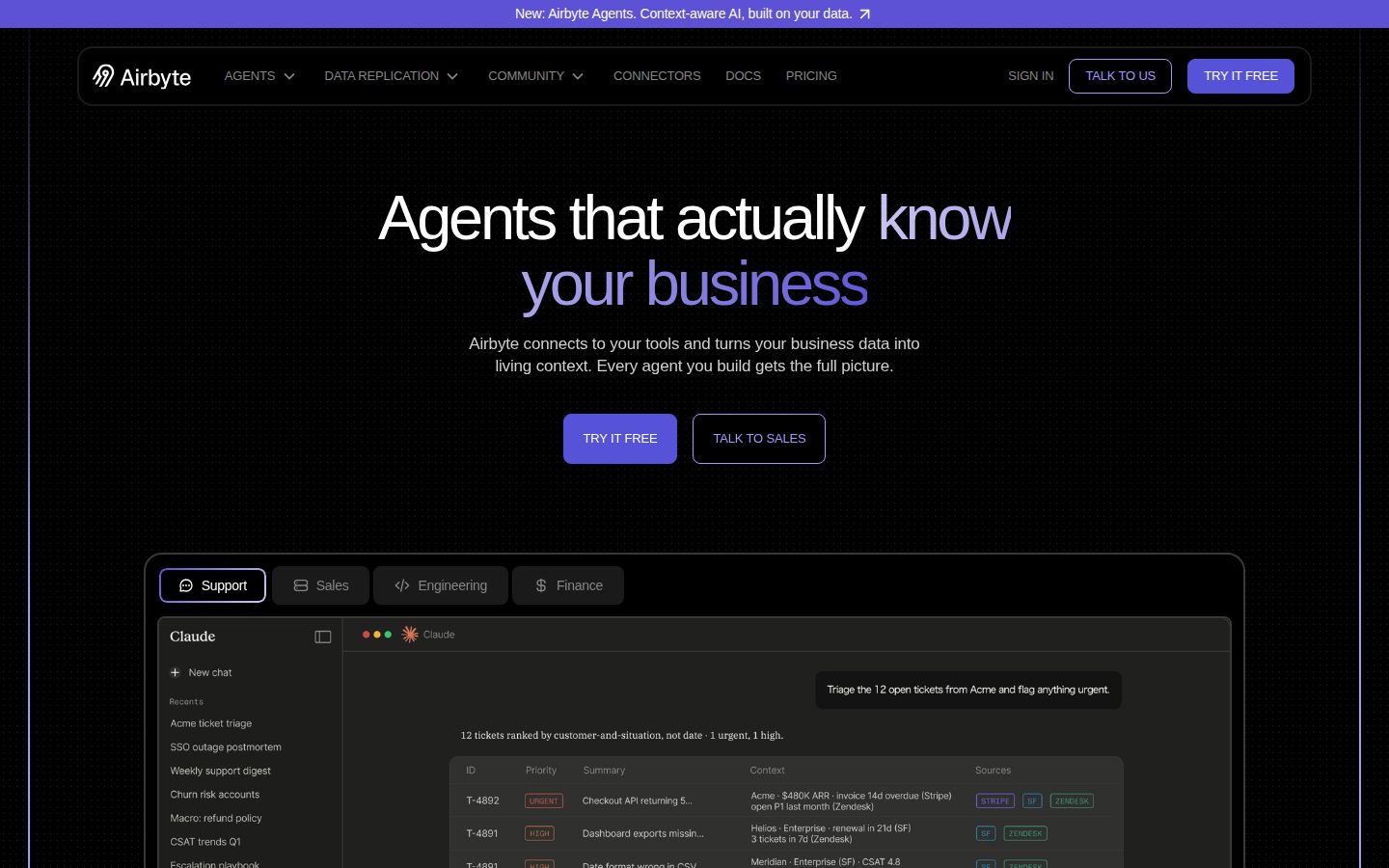
Airbyte lets users set up data pipelines by selecting a source connector, a destination connector, and a sync schedule through a web UI or API. Once configured, Airbyte extracts data from the source, loads it into the destination, and optionally applies transformations. Syncs can be run on a schedule or triggered manually, and users can monitor pipeline status through the platform's interface.
The platform advertises over 600 pre-built connectors spanning CRMs, marketing tools, databases, cloud storage, and analytics platforms. Specific connectors include Marketo, Twilio, TikTok Marketing, Zendesk, QuickBooks, Notion, Firebase, and many others. Airbyte also supports Apache Iceberg-based data lake destinations, a Python SDK called PyAirbyte for scripted pipeline creation, and a connector builder for creating custom connectors when a pre-built one does not exist.
Airbyte targets data engineers, analytics engineers, and technical teams that need reliable, scalable data movement across cloud and on-premise systems. It competes with tools such as Fivetran, Stitch, and Matillion. Airbyte offers an open-source self-hosted version at no cost, a managed cloud offering (Airbyte Cloud) with usage-based pricing, and an enterprise tier for organizations requiring additional support and controls.
Airbyte can be deployed self-hosted via Docker or Kubernetes, or used as a fully managed cloud service. The PyAirbyte library allows integration into Python-based data workflows and notebooks. An API is available for programmatic pipeline management, making it suitable for teams that want to embed data movement into existing orchestration tools like Airflow or Dagster.