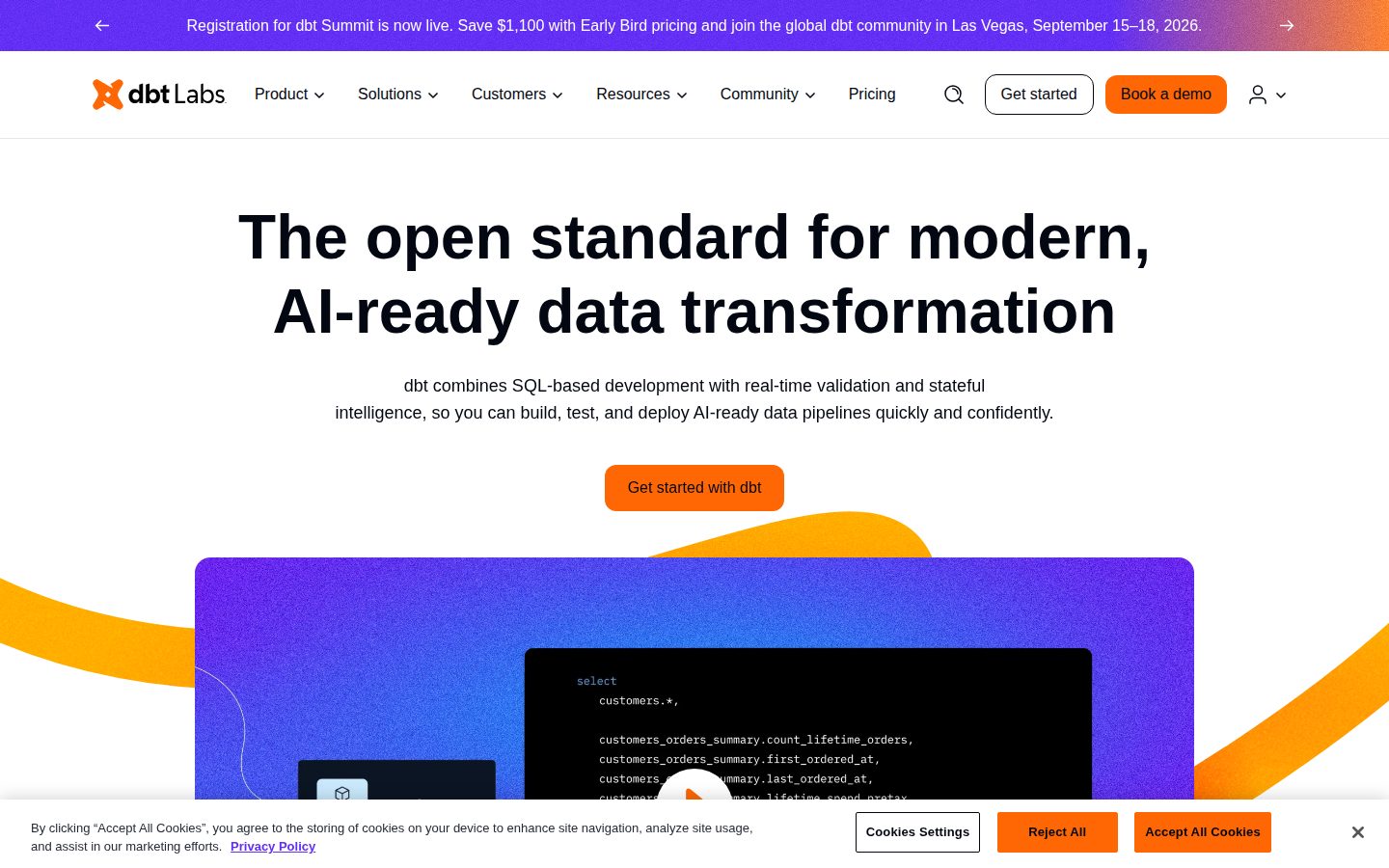
dbt is a command-line tool and framework designed for analytics engineering that enables data teams to transform raw data in their data warehouse using SQL. It allows users to write modular, reusable SQL code that can be version controlled, tested, and documented like software development projects.
The tool is primarily used by data analysts, analytics engineers, and data engineers who need to build reliable data transformation pipelines. dbt works with modern data warehouses including Snowflake, BigQuery, Redshift, and others, allowing teams to leverage the computational power of these platforms while maintaining development best practices.
Key capabilities include SQL-based transformations, automated testing of data quality assumptions, documentation generation, and lineage tracking. dbt also supports macros for reusable code, incremental model builds for performance optimization, and seeds for loading small reference datasets.
The product fits into the modern data stack as the transformation layer, sitting between data ingestion tools and business intelligence platforms. It has gained significant adoption in organizations implementing analytics engineering practices and seeking to apply software engineering principles to their data workflows.