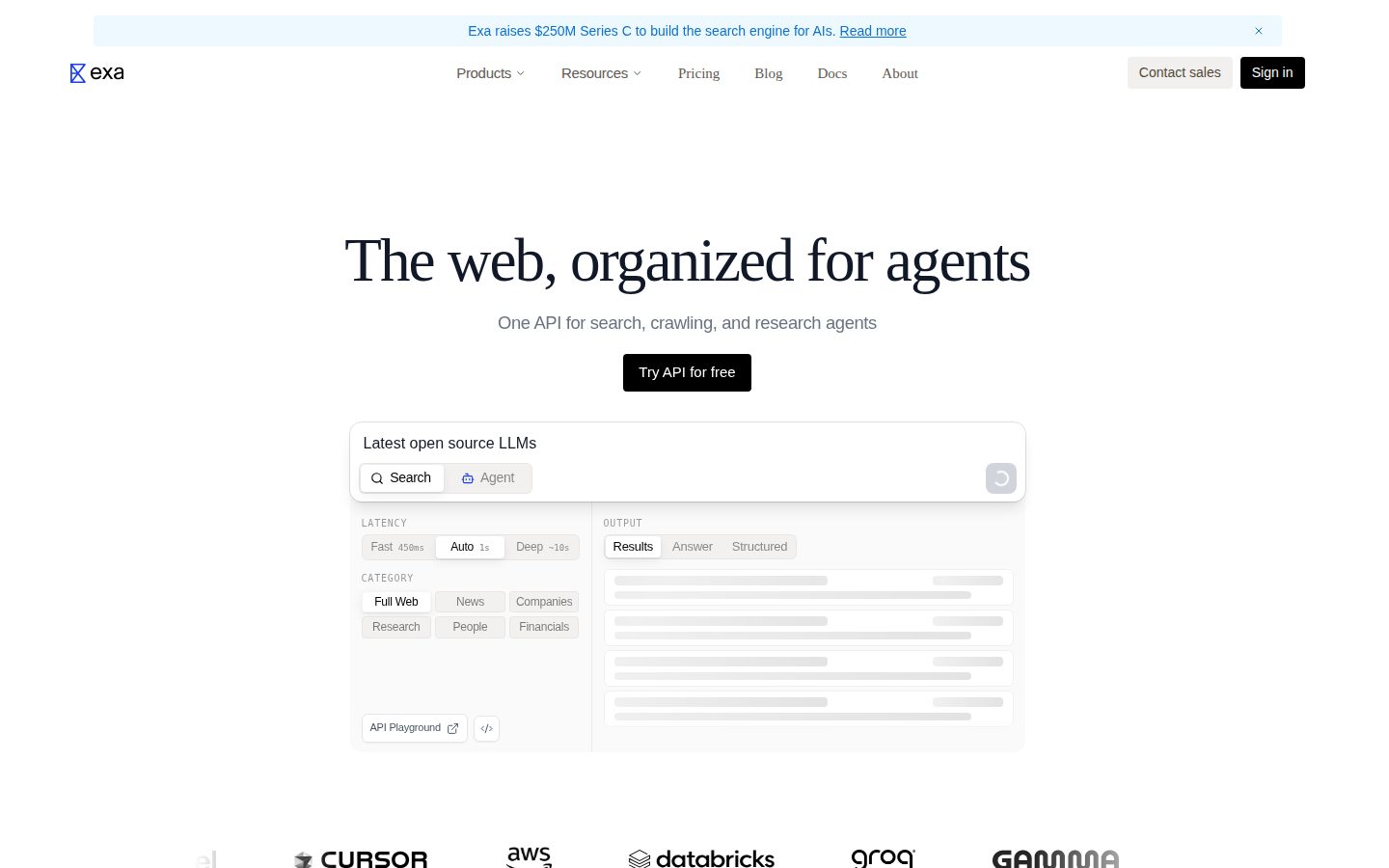
Developers integrate Exa through a REST API to give AI agents access to real-time web data. A typical workflow involves sending a search query to the API, receiving ranked results, and optionally retrieving full page contents or extracted highlights. Latency modes range from under 180ms for instant results to roughly 10 seconds for deep research with structured outputs and grounded citations. Responses can be formatted as plain results, direct answers, or structured JSON objects.
Exa offers several search verticals beyond general web queries: company search, people search, code repositories, news, research papers, and financial data. The highlights feature uses a specialized model to extract the most relevant excerpts from retrieved pages, reducing the token load sent to downstream language models. Structured output mode returns enriched fields—such as CEO name, founding year, and company metadata—across its database of 70 million+ companies. The API also supports a Monitors product for ongoing web surveillance and a DeepAgent mode for multi-step research tasks.
Exa targets AI engineers, agent developers, and companies embedding search into LLM workflows. Named customers include Cognition (Devin), HubSpot, monday.com, CodeRabbit, OpenRouter, Databricks, and StackAI. Competitors in the AI search API space include Perplexity and Brave Search. Pricing is usage-based with a free trial available via the API playground; enterprise plans with zero data retention, SOC 2 Type II compliance, and SSO are available through direct sales.
The product is accessed entirely through a web-based API and API playground. There is no native desktop or mobile application. Integration is API-first, making it platform-agnostic for any backend or agent framework.