In practice, users connect ClearML to their existing Python training scripts with minimal code changes. The platform automatically captures experiment metadata, metrics, artifacts, and environment details. From a central UI or CLI, teams can queue and schedule training jobs, monitor resource usage across GPU clusters, version datasets using Hyperdatasets, and build reproducible pipelines.
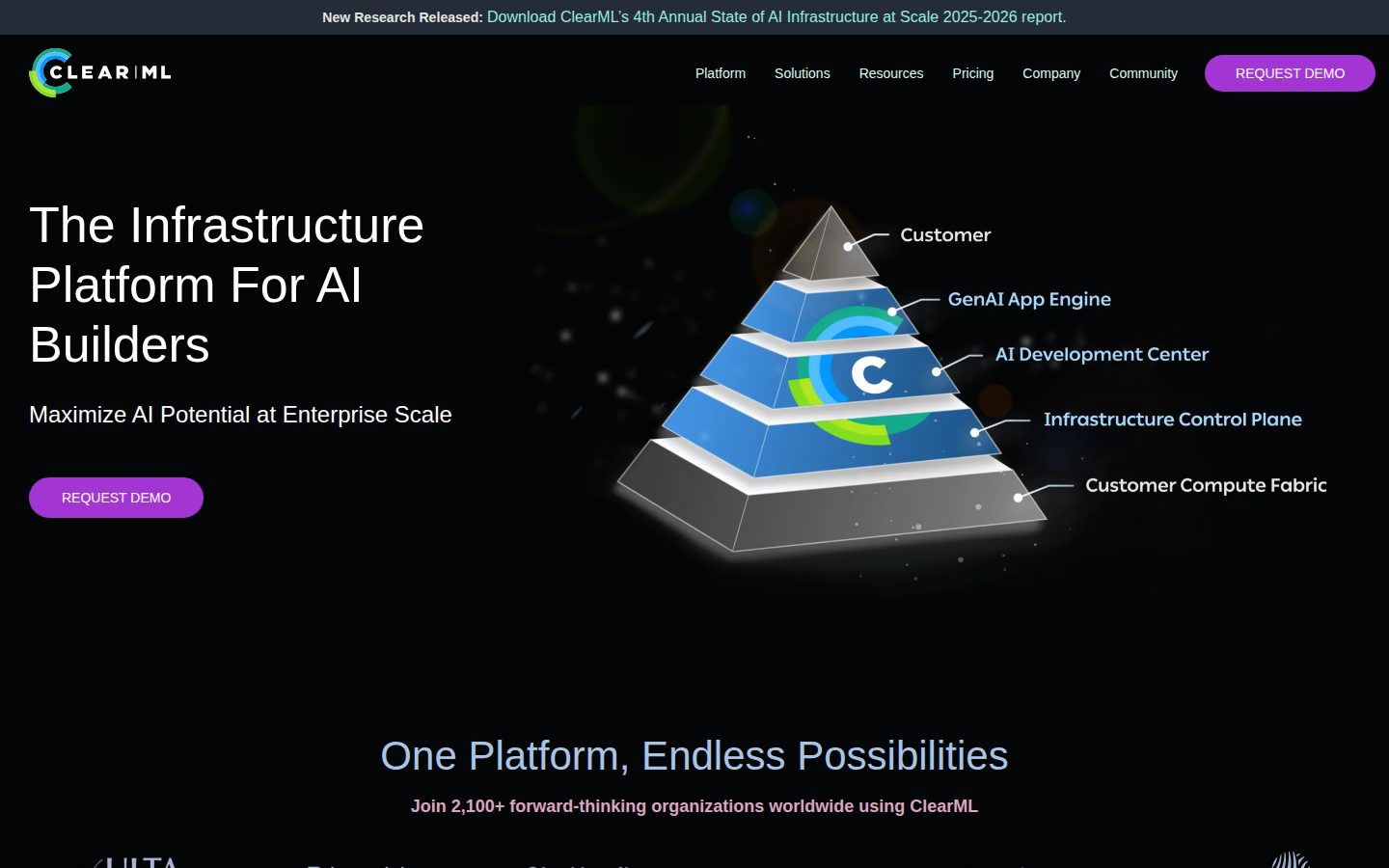
ClearML highlights several specific capabilities on its website: an AI Infrastructure Control Plane for managing GPU clusters (including GPU-as-a-Service for both cloud service providers and enterprise on-prem deployments), an AI Development Center for managing the end-to-end ML lifecycle, and an AI Application Gateway for securing production model serving. The platform integrates with AWS autoscaling, Kubernetes, ArgoCD, Google Colab, and PyTorch, among others.
ClearML targets ML engineers, data scientists, and AI platform teams at companies scaling AI workloads—documented users include Nucleai, Lensor, UVEye, and WSC Sports. The core product is open-source and self-hostable, with a managed cloud offering (ClearML Hosted) that includes a free tier. Paid enterprise plans are available. Competitors in the MLOps category include MLflow, Weights & Biases, Neptune.ai, and Kubeflow.
The platform is accessible via web UI, Python SDK, and CLI. It can be deployed self-hosted on any infrastructure or used as a fully managed SaaS. It supports integration with major cloud providers and container orchestration systems including Kubernetes.