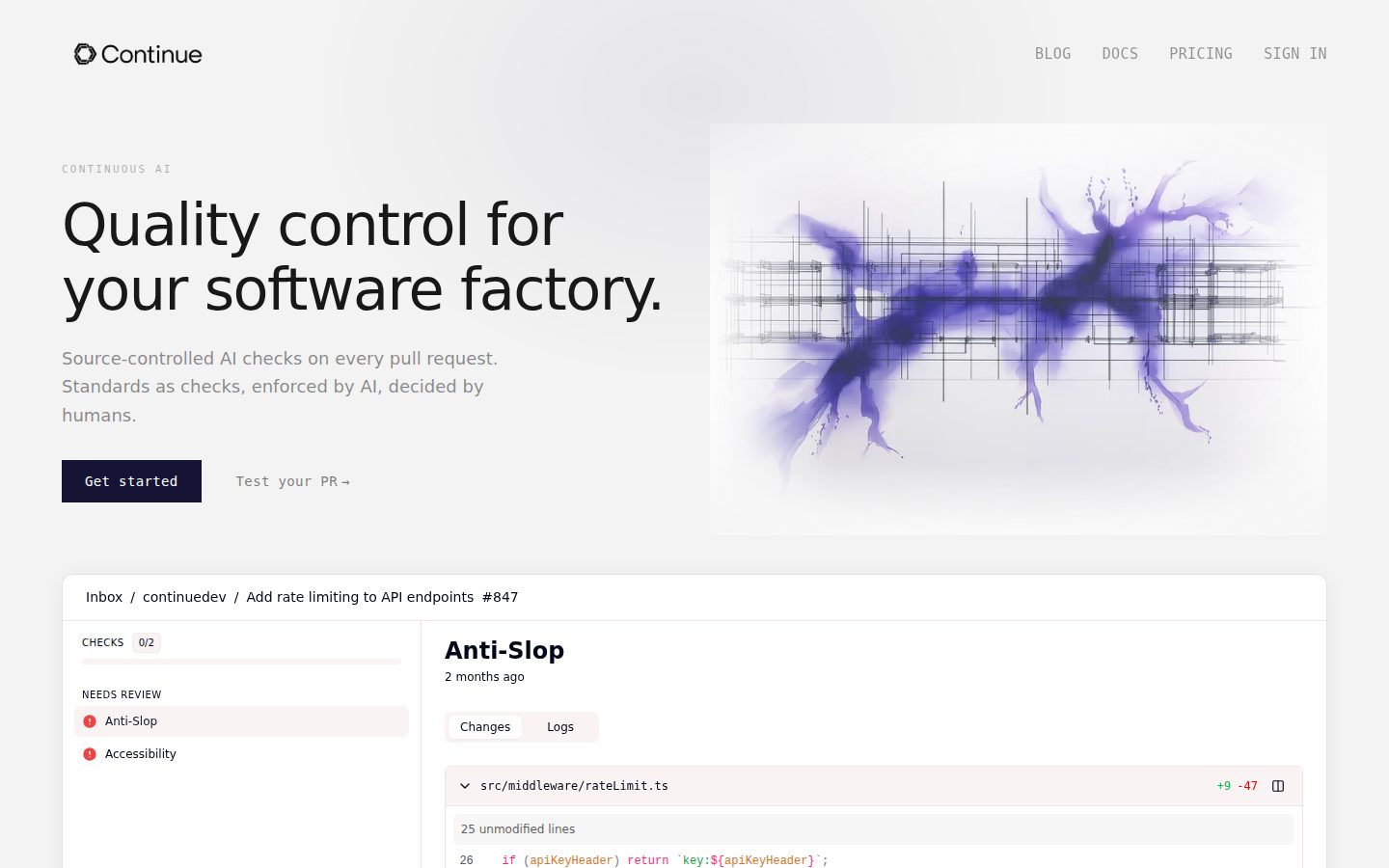
Teams using Continue commit check definitions as markdown files inside their repository (under a .continue/checks/ directory). When a pull request opens, the platform reads the diff, evaluates it against every applicable check, and reports the outcome as a native GitHub status check on the PR. Failing checks include AI-generated suggested fixes that contributors can accept or reject from the GitHub review surface, so the review loop stays inside the existing developer workflow rather than moving into a separate dashboard.
The product positions checks as deterministic enforcement rather than open-ended AI suggestions: a check only flags what its markdown spec describes, which keeps signal high on long-running repositories. Continue also runs as an agent platform — checks are executed by AI agents that can be configured per-repo and per-team — and developers can test a PR ad-hoc through a web entry at continue.dev/check. The open-source core lives at github.com/continuedev/continue, with the hosted service layering credits, team management, and SSO on top.
Continue is built for engineering organizations that already enforce review standards informally and want to mechanize the repetitive parts: platform teams, staff engineers writing house style guides, and security or compliance owners with rules to apply across many repos. Pricing is usage-based starting at $3 per million tokens with no per-seat fee, then $20 per seat per month for the Team tier (which adds private shared agents, agent access controls, and Gmail/GitHub SSO), and custom pricing for the Company tier with SAML/OIDC SSO, bring-your-own API keys, SLAs, and invoiced billing. It overlaps with GitHub Copilot Code Review, CodeRabbit, Greptile, and Qodo for AI PR review, and with traditional linters and policy engines on the rules side.
The platform integrates with GitHub for PR status checks and runs frontier models through credits purchased on the platform; the Company tier supports BYOK so organizations can route through their own model provider accounts. Checks are version-controlled with the rest of the codebase, so rule changes go through the same review process as application code.