In practice, users write Python functions decorated to declare data assets, then compose those assets into jobs. Dagster manages when and how those jobs run—via schedules triggered at set intervals or sensors that fire based on external events. The local development experience mirrors production, so engineers can unit-test and integration-test pipelines before deploying to staging or production clusters.
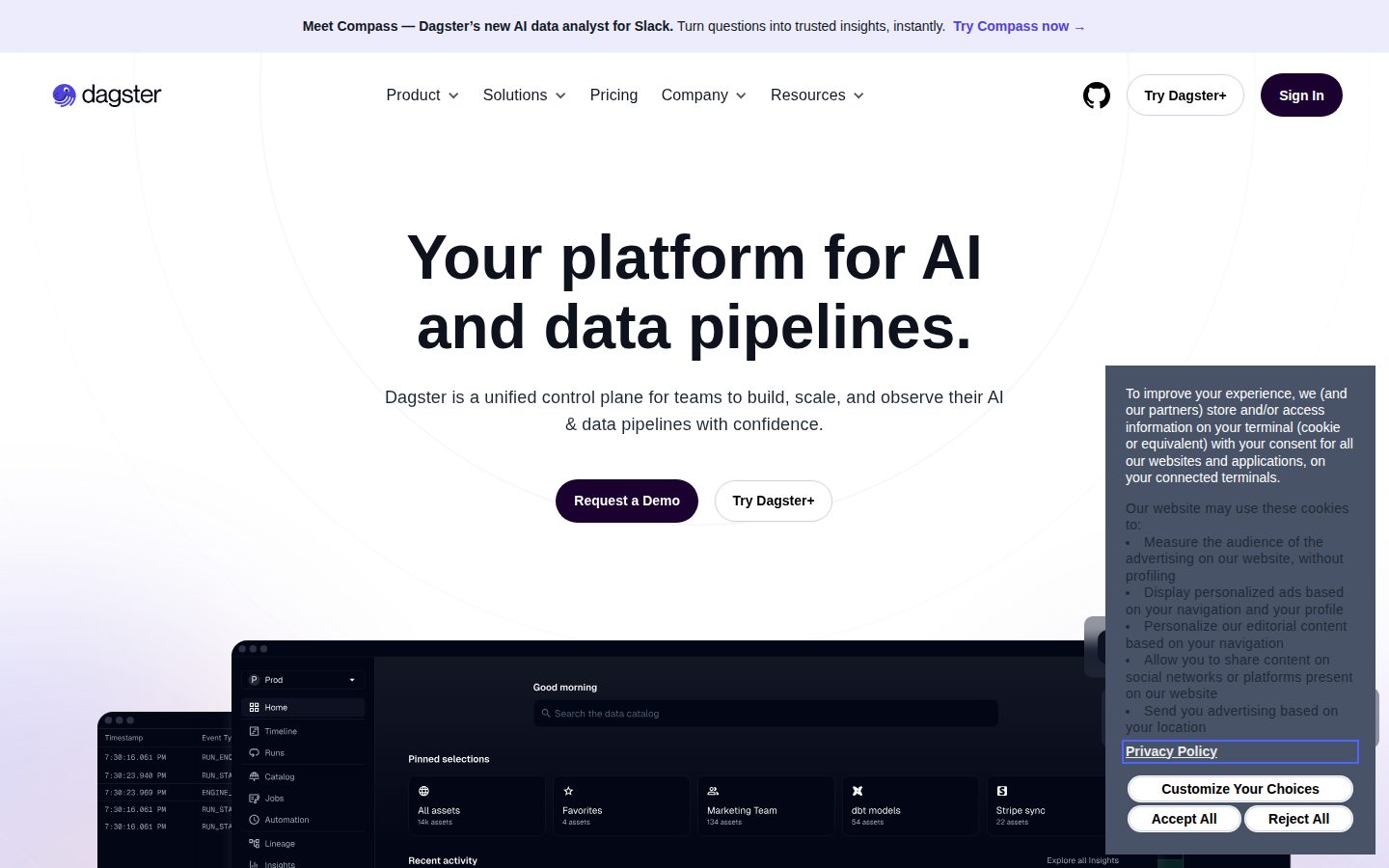
Dagster's built-in observability layer tracks data lineage, monitors data quality, and surfaces operational metadata without requiring external tooling. Partitions allow batch computations to be sliced by time or other dimensions. The platform includes a data catalog for discovering and organizing assets, cost insights for tracking compute spending, and Compass—a Slack-integrated assistant that answers data questions in plain language. Integrations exist for dbt, Snowflake, Spark, Databricks, Airflow, and AWS, among others.
Dagster targets data engineering teams across industries including finance, life sciences, retail, and software. It positions itself against task-centric orchestrators such as Apache Airflow, Prefect, and dbt Cloud. Pricing is tiered, with options ranging from local development use up to an Enterprise plan with additional security and support. A free tier is available for getting started.
Dagster is open source and hosted on GitHub. It can be deployed locally, on self-managed infrastructure, or via Dagster's managed cloud offering. The platform is Python-native and accessed primarily through a web-based UI alongside Python SDKs.